بنية الكلمات
في مقال سابق تحدثت عن الفرق بين اللغات اللصقية والصهرية والتحليلية. اللغات التركية (واللغات الآلطائية بشكل عام) هي لغات لصقية agglutinative. هذا يعني أن بنية الكلمات الآلطائية هي أعقد من بنية الكلمات الصينية (التي تحدثت عنها في هذا المقال).
رغم ذلك فإن الكلمات الآلطائية هي في الحقيقة محكومة بالعديد من القيود التي تقلل من تعقيدها. على سبيل المثال، في الكلمات الآلطائية لا توجد سوابق prefixes ولا دواخل infixes—التصريف والاشتقاق في هذه اللغات يتم دائما عبر إضافة لواحق suffixes إلى جذر الكلمة. هذا يعني أن المقطع الأول من أية كلمة آلطائية هو دائما جذر الكلمة، وفي داخل الجذر لا توجد أية أحرف زائدة. هذه الميزة هي ربما من أهم الميزات التي تميز اللغات الآلطائية عن اللغات التي نشأت في جنوب الصين والتي كان متحدثوها يحملون العلامة Y–Haplogroup O.
أنا ربطت بين (بعض) اللغات الآلطائية وبين العلامة Y–Haplogroup N التي افترضت أنها نشأت في شمال الصين (في حوض النهر الأصفر). العلامة Y–Haplogroup O التي نشأت جنوب الصين (في حوض نهر Yángzǐ) هي مرتبطة بخمس عائلات لغوية كبيرة هي ما يلي (اضغط على اسم العائلة لترى خريطة انتشارها من ويكيبيديا):
من الأمور اللافتة للنظر في لغات هذه العائلات الخمس هو أنها تعتمد على السوابق prefixes والدواخل infixes وليس فقط اللواحق suffixes. السوابق والدواخل لا تظهر حاليا بشكل واضح في الكلمات الصينية، ولكن الباحثين يعتقدون أنها كانت واضحة في اللغة الصينية القديمة Old Chinese (كانت محكية تقريبا في الألفية التي سبقت الميلاد).
أنا لست ملما بشكل كبير بلغات العلامة Y–Haplogroup O، ولكن ما يبدو لي هو أن اللغات الأَوسترۆ-آسيوية والصينية–التيبتية وهمۆنغ–ميان كانت (أو ما زالت) أقرب إلى أن تكون لغات صهرية fusional (على غرار اللغات الهندو–أوروبية Indo–European والأفرو–آسيوية Afro–Asiatic)، وأما اللغات الأَوسترۆنيسية فهي (على ما يبدو) أقرب إلى أن تكون لغات لصقية. سبب ذلك على ما أظن ربما يعود إلى أن اللغات الأَوسترۆنيسية نشأت على الساحل الجنوبي للصين بعيدا عن حوض نهر Yángzǐ (ضمن الثقافة الأركيولوجية المسماة Dabenkeng). متحدثو اللغات الأَوسترۆنيسية لم يمارسوا زراعة الأرز إلا في زمن متأخر نسبيا. هم كانوا بعيدين عن مركز “حضارة الأرز” في حوض Yángzǐ، وربما لهذا السبب لغاتهم حافظت على طابع “بدائي” نسبيا. أنا ذكرت في مقال سابق أن الشعوب “البدائية” أو المعزولة غالبا ما تتحدث لغات لصقية. لا أدري ما هو تفسير هذه الظاهرة، ولكنني أظن أن تحول اللغات اللصقية إلى صهرية ومن ثم إلى تحليلية analytic ربما يكون في الحقيقة مجرد فساد وتشوه لغوي. الحضارات الكبيرة فيها عدد سكان كبير، وهي في الغالب تتوسع وتضم أقواما يتحدثون لغات أجنبية. كثرة السكان ووجود الأجانب الناطقين بلغات أجنبية هي عوامل تشجع على فساد اللغة وتشوهها (أي تحولها إلى لغة صهرية ومن ثم إلى تحليلية). هذا الأمر هو واضح جدا في اللغة الصينية: من يقارن بين اللغة الصينية المعاصرة وبين اللغة الصينية القديمة فسيرى أن هذه اللغة تعرضت لعملية مسخ حقيقية. أحد أسباب هذا المسخ اللغوي (على ما أظن) هو أن كثيرا من الصينيين المعاصرين كانوا في الماضي يتحدثون بلغات أخرى. في العصور القديمة لم يكن هناك تعليم إلزامي ومعظم الناس كانوا أميين لا يقرؤون ولا يكتبون. عندما تمزج الملايين من الأميين الذين يتحدثون لغات مختلفة فكيف تتوقع أن تكون لغتهم؟ هي على الأغلب ستكون شبيهة باللغة الصينية المعاصرة. هذه اللغة هي شبيهة بما يسمى pidgin language (لغة مبسطة بهدف تسهيل استخدامها، والمثال عليها هو اللغة العربية التي يستخدمها الهنود في دول الخليج). كل اللغات الكبرى في رأيي هي هكذا. حتى اللغات السامية والأفرو–آسيوية هي على الأغلب لغات هجينة ومشوهة.
بنية المقاطع
المقاطع الآلطائية بشكل عام تأخذ الشكل التالي:
C₁V(C₂)
الرمزC هو اختصار لـكلمة consonant (“صوت صحة”)، والرمز V هو اختصار لـكلمة vowel (“صوت علة”). وجود الرمز الذي بين قوسين هو اختياري.
في اللغات الآلطائية هناك عدد لا يستهان به من الجذور roots واللواحق suffixes التي لا تبدأ بصوت صحيح V(C)، ولكن هناك مؤشرات على أن كثيرا منها هي محرفة بإسقاط الصوت الصحيح الأول منها *C₁V(C₂) > V(C₂).
كثير من الجذور التركية التي من الشكل V(C) كانت في اللغة التركية البدائية Proto-Turkic تبدأ بصوت الهاء *h̞– الناتج من تنفيس spirantization الصوتين *p– و *g–. حاليا صوت الهاء *h̞– الموروث من اللغة التركية البدائية هو مفقود بشكل شبه كامل من معظم اللغات التركية ما عدا لغة الخَلَج Khalaj في إيران. سقوط البادئة *h̞–من الجذور حولها من الشكل *h̞V(C) إلى الشكل V(C).
اللواحق التي من الشكل –V(C) نشأت أيضا من تنفيس صوتها الأول*–C₁V(C₂) > –V(C₂) . هذه الظاهرة هي موثقة. مثلا في اللغة التركية القديمة Old Turkic كانت هناك العديد من اللواحق التي تبدأ بالصوت *–G (الرمز G يعني كلا من النظيرين الأمامي g والخلفي g̣) ولكن هذه اللواحق تظهر في اللغة الأناضولية المعاصرة دون هذا الصوت. مثلا اللاحقة الأناضولية المعاصرة –(y)ᴀn التي تستخدم لصياغة المشتق المسمى present participle كانت في اللغة التركية القديمة بهذا الشكل *–Gᴀn (مثلا العبارة الأناضولية المعاصرة gälän kiši “الشخص الآتي” كانت في التركية القديمة هكذا kälgän kiši). لاحقة الإعطاء dative suffix التي تحمل معنى حرف الجر “إلى” كانت في اللغة التركية القديمة بهذا الشكل –Kᴀ (الرمز K يعني كلا من النظيرين الأمامي k والخلفي ḳ). هذا الشكل ما زال موجودا في لغة الخَلَج Khalaj (مثلا في لغة الخَلَج كلمة häḇ تعني “بيت”، و häḇkä تعني “إلى البيت”). في اللغة الأناضولية المعاصرة شكل لاحقة الإعطاء هو *–Ḡᴀ > –(y)ᴀ (مثلا في اللغة الأناضولية المعاصرة كلمة äḇ تعني “بيت”، و *äḇḡä > äḇä تعني “إلى البيت”).
من المحتمل أيضا أن التحول *–C₁V(C₂) > –V(C₂) حصل في اللواحق أحيانا بسبب ظاهرة القُطْعَة الوسطية syncope. هناك مؤشرات على أن متحدثي اللغات التركية والمنغولية كانوا قديما يميلون إلى تركيز نبرة الصوت stress على الجذر، وهذا أضعف اللواحق وجعل أصواتها عرضة للسقوط. نفس هذه الظاهرة هي ربما السبب الذي أدى لسقوط أصوات العلة (القصيرة؟) من أواخر الكلمات التركية.
المقاطع الآلطائية يمكن أن تكون من الشكل CV أو C₁VC₂. في اللغات التركية الشكل الثاني هو أشيع بكثير في الجذور، ربما بسبب سقوط أصوات العلة من أواخر الكلمات*C₁V₁.C₂V₂ > C₁V₁C₂ . الشكل C₁VC₂ يسمى “مقطعا مغلقا” closed syllable لأنه ينتهي بصوت صحيح، والشكل CV يسمى “مقطعا مفتوحا” open syllable لأنه ينتهي بصوت عليل.
على ما يبدو فإن بعض المقاطع الآلطائية المغلقة C₁VC₂ كانت قديما مفتوحة CV ولكنها أغلقت بإضافة أصوات صحيحة إلى أواخرها. Juha Janhunen ذكر أمرا لافتا وهو أن اللغة المنغولية البدائية Proto-Mongolic لم تكن تحوي جذوعا فعلية تنتهي بأصوات أنفية *ŋ, *n, *m. بعض الجذوع الاسمية في هذه اللغة كانت تنتهي بأصوات أنفية، ولكن الأصوات الأنفية كانت تُزال من غالبية هذه الجذوع عند إضافة لاحقة الجمع *–d. مثلا الكلمة المنغولية البدائية *ḳaḡ̣an > *ḳahan تعني “أمير” prince (هذه الكلمة هي مصدر كلمة “خان” ḳ̄a̱n التي تظهر مثلا في اسم “چنگیز خان” ᠴᠢᠩᠭᠢᠰ ᠬᠠᠭᠠᠨ ᵗšiŋgis ḳahan)؛ الشكل المجموع لكلمة *ḳahan هو *ḳahad (الصوت *–n أزيل من الجذع وأضيفت مكانه لاحقة الجمع *–d). الكلمة المنغولية البدائية *morin تعني “حصان” horse؛ الشكل المجموع لهذه الكلمة هو *morid.
في اللغة المنغولية البدائية لاحقة النصب accusative هي بهذا الشكل *–i عند إضافتها إلى الجذوع المنتهية بأصوات صحيحة وبهذا الشكل *–yi عند إضافتها إلى الجذوع المنتهية بأصوات علة. عند إضافتها إلى الجذوع المنتهية بأصوات أنفية هي كانت في الغالب تأخذ الشكل *–yi بعد حذف النون؛ مثلا الشكل المنصوب لكلمة *morin هو Janhunen .*moriyi يعتبر هذا مثالا إضافيا على ظاهرة حذف النون من الجذع، ولكنني أشك في ذلك. من الممكن في رأيي أن كلمة *moriyi نشأت من *morini بتغوير النون palatalization (مثلما أن كلمة *Kitayi > Kitay نشأت من *Kitani إلخ).
حسب Janhunen فإن ظاهرة حذف الصوت الأخير من الجذع كانت تحصل أيضا عند إضافة لاحقة الجمع *–d إلى جذوع اسمية تنتهي بأصوات سائلة *r, *l.
Janhunen يرى أن الأصوات الأنفية والسائلة التي تزال من نهاية الجذوع الاسمية المنغولية هي في الأصل لواحق اشتقاقية derivative suffixes. أنا قرأت هذه المقولة أكثر من مرة ولكنني لم أقرأ أي شيء يثبتها. ما يبدو لي هو أن إضافة الأصوات الأنفية والسائلة إلى نهاية بعض المقاطع المنغولية كانت ظاهرة صوتية بحتة لا علاقة لها بالاشتقاق أو التصريف. هذه الظاهرة أدت إلى إغلاق الكثير من المقاطع المفتوحة *CV > C₁VC₂. أنا أظن أن نفس هذه الظاهرة حصلت أيضا في اللغة ما قبل التركية البدائية Pre-Proto-Turkic.
Janhunen ذكر أن اللاحقة التسببية causative التي كانت تضاف في اللغة المنغولية البدائية إلى الجذوع الفعلية المنتهية بأصوات صحيحة هي *–ka أو *–ga، في حين أن نظيرتها التي كانت تضاف إلى الجذوع المنتهية بأصوات علة هي *–lga. صوت اللام في بداية اللاحقة الأخيرة هو ربما مثال إضافي على ظاهرة إغلاق المقاطع المفتوحة عبر إضافة صوت سائل. لا أظن أن وجود صوت اللام في بداية *–lga له أي معنى نحوي أو صرفي. هناك أمثلة أخرى مشابهة يمكن استخلاصها مما ذكره Janhunen عن لواحق اللغة المنغولية البدائية.
خلاصة ما سبق هي أن المقاطع الآلطائية تأخذ في الغالب الشكلين CV أو C₁VC₂، ويبدو أن بعض المقاطع من الشكل المفتوح CV اختفت إما بسبب سقوط صوت العلة منها *CV > C أو بسبب إغلاقها بصوت أنفي أو سائل *CV > C₁V₁C₂.
المقاطع من الشكل C₁V(C₂) هي أيضا المقاطع الشائعة في اللغات الأَوسترۆنيسية Austronesian. الجذور الأَوسترۆنيسية يمكن أن تأخذ سوابق prefixes من الشكل CV– أو CVN– (حيث N تعني صوتا أنفيا nasal كالنون أو الميم)[1]. بالنسبة لمقاطع اللغات الأَوسترۆ-آسيوية Austroasiatic ولغات همۆنغ-ميان Hmong-Mien واللغات الصينية-التيبتية Sino-Tibetan فهي يمكن أن تأخذ شكلين هما C₁VC₂ أو C₁C₂VC₃. الشكل الثاني C₁C₂VC₃ نشأ على الأغلب من إضافة سوابق prefixes أو دواخل infixes، لأن مثل هذه العملية هي شائعة في هذه اللغات. السوابق في هذه اللغات تسمى غالبا بأسماء من قبيل minor syllables (“مقاطع صغرى”) أو preinitials (“ما قبل بوادئ”). هي في الغالب تأخذ الشكل CV– أو CVN–، وصوت العلة فيها هو في الغالب صوت مختزل reduced، أي أنه صوت ضعيف وقصير يمكن التعبير عنه بهذا الرمز ə. هذا الصوت كثيرا ما يختفي، وهذا ما يؤدي إلى ظهور عناقيد أصوات صحة consonant clusters في بوادئ الكلمات C₁ə–C₂VC₃ > C₁C₂VC₃. الدواخل infixes في هذه اللغات تسمى غالبا “أواسط” medials. هي دائما إما أصوات سائلة liquid (اللام أو الراء) أو أصوات سلسة glide (الواو أو الياء)، وهي تلتصق بالصوت الصحيح الأول من الجذر، فتكون النتيجة مقاطع من الشكل C₁C₂VC₃، حيث الصوت C₂ هو الداخلة أو العنصر الوسطي medial.
اللغة اليابانية (وخاصة اللغة اليابانية القديمة Old Japanese) تمتاز عن بقية اللغات الآلطائية بأن معظم مقاطعها هي مفتوحة CV. ما يلي يتعلق بهذا الموضوع:
One of the obstacles that prevents us from reaching a consensus about the genetic affiliation of Japanese is its syllabic structure. The occurrence of consonant clusters in medial position is a phonological feature that is shared by Korean and the Altaic languages, but, on the face of it, not by Japanese. Japanese is a textbook example of a language with a relatively simple syllable structure, and the structure of Old Japanese was even simpler. All Old Japanese syllables had a (C)V structure and V syllables were restricted to word-initial position. In his survey of the languages of Japan, Shibatani (1990: 101) refers to this problem by saying: “The most embarrassing problem for anyone attempting to relate Japanese to the Altaic family or to Korean is the phonological discrepancy between the former and the latter. Japanese, especially Old Japanese, basically has a CV syllable structure, whereas Altaic languages and Korean abound in closed syllables with a variety of syllable-final consonants”. In a manuscript dealing with Altaic elements in Old Japanese, the same problem was pointed out by Miller and Street (1975: 146): “The most serious problem encountered thus far in developing these statements involves possible OJ [=Old Japanese] reflexes of pA [=Proto-Altaic] consonant clusters. J [=Japanese] is basically a CV-CV- language; pA had rather CV(C)-CV(C). If J derives from pA as presently reconstructed, it has either simplified older clusters or added vowels. (…) hence it will take a great amount of further investigation to determine what the normal J reflex was in each case where pA indicates a cluster”.
The so-called phonological discrepancy has the effect of making researchers turn their attention to other languages and language families with relatively simple phonological systems like Austronesian. The fact that Japanese typically has open syllables and an uncomplicated consonant system also leads to the assumption that Japanese has an Austronesian substratum. It further leads to a number of Austronesian-Altaic hybrid or mixed language hypotheses, describing Japanese as a mixture of elements originating from two different language families, Altaic and Austronesian. A serious problem is that the assumption of a linguistic connection between Japanese and Austronesian is not compatible with the archeological record because there is no evidence that a substantial number of Austronesian speakers reached Japan in prehistory.
Martine Robbeets (2008), “If Japanese is Altaic, why is it so simple?” pp. 337-338
بعض الباحثين اقترحوا أن اللغة اليابانية خضعت لتأثير كبير من لغة يعود أصلها إلى جنوب الصين (هم في العادة يفترضون أن هذه اللغة تنتمي إلى العائلة الأَوسترۆنيسية Austronesian). حسب هذه النظرية فإن اللغة اليابانية هي لغة هجينة نشأت من امتزاج لغة آلطائية مع لغة أخرى قادمة من جنوب الصين. كاتبة الكلام أعلاه ترفض هذه النظرية بحجة أنها غير مدعومة بأدلة أركيولوجية، ولكن الحقيقة هي أن هذه النظرية تتناسب مع نتائج الدراسات الجينية التي أجريت في اليابان: الدراسات الجينية التي أجريت في اليابان بينت أن غالبية الذكور اليابانيين يحملون فروعا من العلامة Y-Haplogroup O.

العلامة Y-Haplogroup O نشأت على الأغلب في القسم الجنوبي من الصين، وانتشارها من هناك كان على الأغلب مرتبطا بانتشار زراعة الأرز (زراعة الأرز بدأت في حوض نهر يانغتسي Yángzǐ قبل حوالي 7000 عام). وجود العلامة Y-Haplogroup O لدى غالبية الذكور اليابانيين والكوريين هو (في رأيي على الأقل) دليل قوي على أن أصول غالبية اليابانيين والكوريين تعود إلى جنوب الصين.
الأدلة الأركيولوجية تظهر أن اليابان شهدت في حدود 300 قبل الميلاد وصول مهاجرين جدد من جنوب كوريا. هؤلاء كانوا يمارسون زراعة الأرز “الرطبة” wet في “حقول البادي” paddy fields (الحقول المغطاة بمياه ضحلة). هذا الأسلوب في زراعة الأرز لم يكن معروفا قبل ذلك في الجزر اليابانية. هؤلاء المهاجرون الجدد يسمون Yayoi (نسبة إلى موقع أثري في طوكيو). الـ Yayoi هم على الأغلب الذين أدخلوا اللغة اليابانية إلى الجزر اليابانية. قبل وصولهم كان سكان اليابان يتحدثون لغات محلية لا علاقة لها باللغة اليابانية أو بأية لغات محكية خارج اليابان. إحدى هذه اللغات هي لغة الأَيْنُو Ainu التي ما زالت توجد إلى الآن في شمال اليابان. العلامة الجينية الغالبة على شعب الأَيْنُو هي العلامة Y-Haplogroup D. هذه العلامة هي موجودة بنسبة مهمة لدى جميع اليابانيين بغض النظر عن لغاتهم، ما يدل على أن كثيرا من متحدثي اللغة اليابانية كانوا في السابق يتحدثون بلغات محلية قبل أن يبدلوا لغاتهم. البقايا الأركيولوجية لسكان اليابان قبل وصول الـ Yayoi تسمى Jōmon culture.
لا أعرف بالضبط متى وصلت زراعة الأرز إلى شبه الجزيرة الكورية، ولكن يبدو أن زراعة الأرز الرطبة (في حقول البادي) كانت ممارسة في كوريا منذ القرن التاسع قبل الميلاد ضمن الثقافة الأركيولوجية المسماة Middle Mumun.
لو جمعنا كل المعطيات فيمكننا أن نرسم السيناريو التالي:
مزارعو الأرز الذين يحملون فروعا من العلامة Y-Haplogroup O هاجروا من حوض نهر Yángzǐ باتجاه الشمال نحو شبه الجزيرة الكورية واليابان. هم وصلوا إلى شبه الجزيرة الكورية في حدود 1000 قبل الميلاد، ووصلوا إلى اليابان في حدود 300 قبل الميلاد.
خلال هذه الهجرة الطويلة هم احتكوا مع شعوب آلطائية كانت تسكن في شمال شرق الصين وجنوب مَنْجوريا. الامتزاج بين لغات الشعوب الآلطائية المحلية وبين لغات المهاجرين القادمين من الجنوب أنتج اللغتين اليابانية والكورية.
اللغة اليابانية لم تمض وقتا طويلا بجوار الآلطائيين: متحدثو اللغة اليابانية عبروا من جنوب كوريا إلى اليابان في حدود 300 قبل الميلاد، وبعد ذلك هم انعزلوا وانقطعت صلتهم مع بقية الآلطائيين. لهذا السبب الشبه بين اللغة اليابانية وبين بقية اللغات الآلطائية هو ضعيف. الكوريون ظلوا لزمن أطول على احتكاك مع الآلطائيين. لهذا السبب لغتهم هي أكثر شبها باللغات الآلطائية من اللغة اليابانية.
بعض النظريات تفترض أن المهاجرين الذين أدخلوا زراعة الأرز الرطبة إلى اليابان (وكوريا؟) وصلوا عبر البحر. السبب الأساسي لهذه الفرضية (على ما أظن) هو رغبة البعض في إيجاد صلة بين اليابانيين وبين اللغات الأَوسترۆنيسية Austronesian التي نشأت في جزيرة تايوان وانتشرت من هناك عبر البحر. أنا لا أدري ما هو مدى قوة الربط بين اللغة اليابانية واللغات الأَوسترۆنيسية من الناحية اللغوية، ولكنني أشك في كونه مبنيا على أدلة جدية. من الممكن أن السبب الرئيسي لهذا الربط هو كون اللغات الأَوسترۆنيسية ذات طابع لصقي agglutinative، وهذا ربما يجعلها ظاهريا أشبه باللغة اليابانية واللغات الآلطائية من بقية اللغات التي كانت محكية في جنوب الصين.
أنا أظن أن جميع اللغات التي كانت محكية في جنوب الصين كانت في البداية ذات طابع لصقي لا يختلف عن طابع اللغات الأَوسترۆنيسية. في رأيي أن تحول هذه اللغات إلى طابع صهري ومن ثم تحليلي هو تطور حديث نسبيا.
نتائج الدراسات الجينية لا تدعم الربط بين اللغة اليابانية واللغات الأَوسترۆنيسية. نتائج الدراسات الجينية تدل على أن اليابانيين والكوريين (وبعض المَنْجوريين) يملكون فرعا خاصا من العلامة Haplogroup O هو العلامة المسماةHaplogroup O2b-M176 . أقرب العلامات إلى هذه العلامة هي العلامة المسماة Haplogroup O2a1-M95 التي تميز متحدثي اللغات الأَوسترۆ-آسيوية Austroasiatic.
ما يلي خريطة توضح المواطن المحتملة لفروع العلامة Y-Haplogroup O. هذه الخريطة هي مجرد نظرية أولية من عندي وليست شيئا مثبتا:
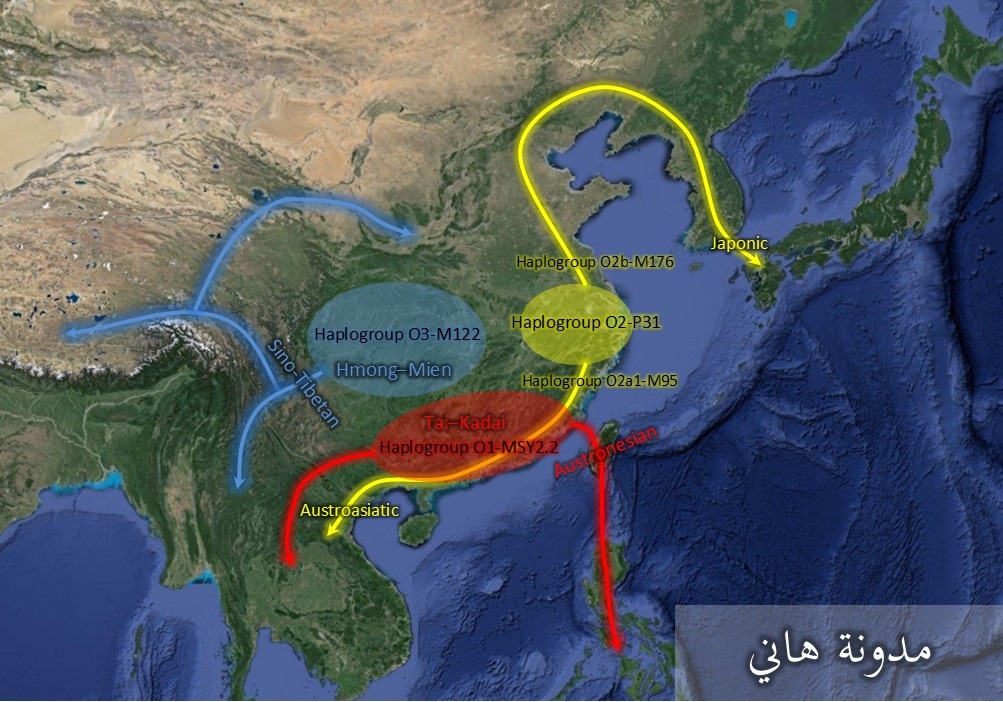
باحثو الجينات يقسمون العلامة Haplogroup O إلى ثلاثة فروع كبيرة يسمونها Haplogroup O1-MSY2.2 و Haplogroup O2-P31 و Haplogroup O3-M122 (أحدث التسميات هي موجودة في هذه الصفحة). نتائج الدراسات الجينية توحي بأن حملة الفرع الثاني Haplogroup O2-P31 كانوا في الأصل يسكنون في القسم الشرقي من حوض نهر Yángzǐ بالقرب من ساحل بحر الصين الشرقي. هؤلاء تمددوا في اتجاهين:
۞ قسم تمدد جنوبا على ساحل بحر الصين إلى أن وصل إلى شبه جزيرة الهند الصينية—هذا القسم حمل العلامة Haplogroup O2a1-M95
۞ قسم تمدد شمالا على ساحل البحر الأصفر إلى أن وصل إلى كوريا واليابان—هذا القسم حمل العلامة Haplogroup O2b-M176
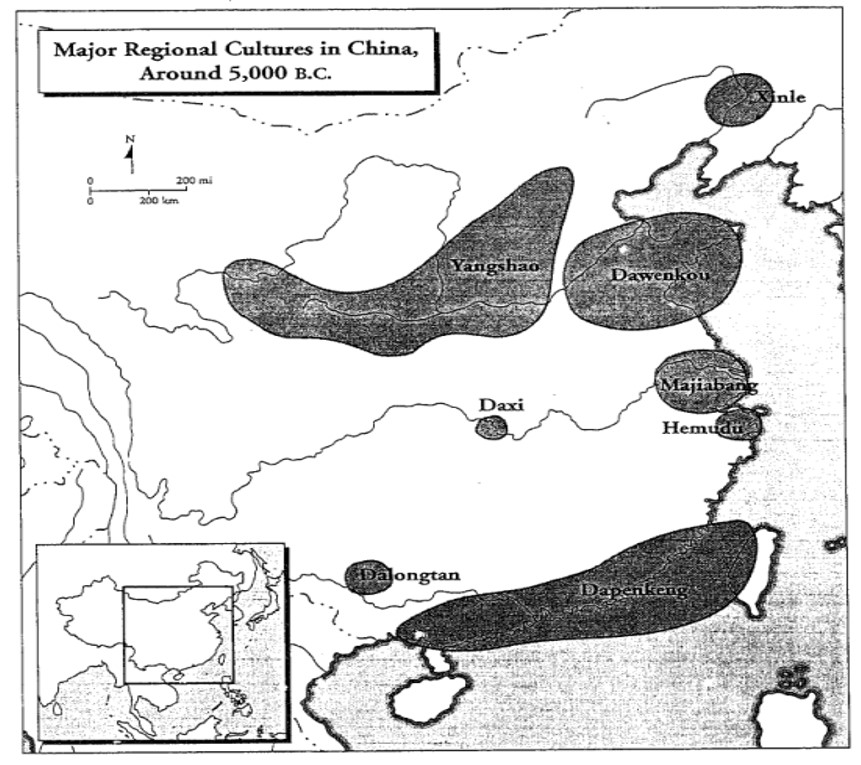
الموطن الأصلي لحملة العلامة Haplogroup O2-P31 ربما كان الثقافتين المسماتين Majiabang وHemudu عند مصب نهر Yángzǐ وعلى سواحل خليج Hángzhōu. هاتان الثقافتان تربطان أحيانا باللغات الأَوسترۆنيسية، ولكنني أشك في وجود دليل حقيقي يدعم هذا الربط. من الممكن أن العلامة Haplogroup O2a1-M95 نشأت في ثقافة Hemudu (الجنوبية) والعلامة Haplogroup O2b-M176 نشأت في ثقافة Majiabang (الشمالية). ثقافة Majiabang هي ربما مصدر أجداد اليابانيين والكوريين، وثقافة Hemudu هي ربما مصدر أجداد الأَوسترۆ-آسيويين. ثقافة Dawenkou (التي تقع إلى الشمال من ثقافة Majiabang) كانت تقوم على زراعة الدُّخْن millet، وعلى الأغلب أنها كانت ثقافة آلطائية. لا يوجد سبب حقيقي (في رأيي) للافتراض بأن ثقافة Dawenkou كانت ثقافة أَوسترۆنيسية (كما يقول Laurent Sagart). الموطن الأصلي للغات الأَوسترۆنيسية هو على الأغلب ثقافة Dabenkeng. هذه الثقافة تمددت نحو جزيرة تايوان، وهذا يتناسب تماما مع تاريخ اللغات الأَوسترۆنيسية كما نعرفه. هذه الثقافة كانت في بدايتها لا تزرع الأرز، ولكن زراعة الأرز وصلت إليها في حدود 3000 قبل الميلاد. من الممكن أن وصول زراعة الأرز إلى هذه الثقافة هو مرتبط بهجرة أجداد الأَوسترۆ-آسيويين من الشمال باتجاه الهند الصينية. العلامة الجينية المميزة للعائلة الأَوسترۆنيسية هي العلامة Haplogroup O1-MSY2.2. هذه العلامة هي مميزة أيضا لعائلة Tai–Kadai. هذا يتناسب مع النظريات اللغوية التي قالت أن اللغات الأَوسترۆنيسية ولغات Tai–Kadai لها أصل مشترك (Laurent Sagart ذهب إلى حد القول بأن لغات Tai–Kadai هي مجرد فرع من العائلة الأَوسترۆنيسية تعرض لتأثير كبير من لغات أخرى). الأصل المشترك للغات الأَوسترۆنيسية ولغات Tai–Kadai ربما كان محكيا في ثقافة Dabenkeng (قبل أن يخترقها زراعو الأرز القادمون من الشمال؟).
الثقافة المسماة Daxi (في القسم الأوسط من حوض نهر Yángzǐ) هي ربما موطن العائلة اللغوية المسماة همۆنغ-ميان Hmong-Mien. الدراسات الجينية بينت أن متحدثي لغات هذه العائلة يحملون العلامةHaplogroup O3-M122 . هذه العلامة هي أيضا علامة العائلة الصينية-التيبتية Sino-Tibetan. من الممكن أن ثقافة Daxi هي أيضا الموطن الأصلي للعائلة الصينية-التيبتية، بمعنى أن عائلة همۆنغ-ميان والعائلة الصينية-التيبتية ربما كان لهما أصل مشترك كان محكيا في ثقافة Daxi. من الممكن أيضا أن موطن العائلة الصينية-التيبتية كان يقع إلى الغرب أو الجنوب الغربي من ثقافة Daxi بالقرب من هضبة التيبت، ومن هناك صعد متحدثو لغات هذه العائلة إلى هضبة التيبت قبل حوالي 4000 عام (وبعضهم نزل لاحقا إلى الهند الصينية وكون الفرع البورمي Burmic من اللغات الصينية-التيبتية).
هذه الطروحات ليست أكيدة، ولكنها تبدو لي حاليا الأكثر تناسبا مع الأدلة، خاصة نتائج الدراسات الجينية.
الخلاصة هي أن المهاجرين الذين أوصلوا زراعة الأرز إلى كوريا واليابان ربما أتوا من ثقافة Majiabang على ساحل بحر الصين الشرقي. هؤلاء كانوا يمتون بصلة قرابة جينية إلى متحدثي اللغات الأَوسترۆ-آسيوية Austroasiatic، ومن الوارد أن لغاتهم كانت شبيهة بهذه اللغات.
Martine Robbeets (التي نقلت كلامها في الأعلى) طرحت نظرية مفادها أن الكلمات اليابانية كانت في الأصل ذات بنية شبيهة ببنية الكلمات الآلطائية C₁V₁C₂–C₃V₂(C₄)، ولكن اليابانيين (في زمن باكر) غيروا بنية الكلمات إلى الشكل C₁V₁NC₂V₂(C₃) (حيث N تعني صوتا أنفيا nasal). ما فعلوه هو أنهم استبدلوا العناقيد الوسطية –CC– medial clusters بعناقيد تبدأ بصوت أنفي –NC–. لاحقا الصوت الأنفي اندمج مع الصوت الصحيح التالي له وحوله إلى صوت مجهور voiced (حسب Robbeets فإن اللغة اليابانية أصلا لم تكن تحوي أصواتا مجهورة). في النهاية بنية الكلمات اليابانية صارت من الشكل C₁V₁–C₃V₂.
على سبيل المثال، Robbeets تقول أن الكلمة اليابانية القديمة *santa– لها نفس أصل الكلمة الطُّنْغوسية *sädki–. الكلمة اليابانية القديمة تحولت لاحقا إلى sada–. هذه الكلمة هي مصدر الكلمة اليابانية المعاصرة sadameru التي تعني “قرار” decide. الكلمة اليابانية القديمة *anpu– لها نفس أصل الكلمة الطُّنْغوسية والمنغولية *abga. الكلمة اليابانية القديمة تحولت لاحقا إلى abu–. هذه الكلمة هي مصدر الكلمة اليابانية المعاصرة abunai التي تعني “خطير” dangerous.
Robbeets ترى أن نظريتها تثبت أن اللغة اليابانية هي ليست لغة هجينة، ولكنني لا أدري على أي أساس تقول هذا الكلام. التطور الذي تقول أنه حصل في اللغة اليابانية الباكرة هو على ما أظن ليس تطورا صوتيا عاديا. مثل هذا التطور يدل على أن غالبية متحدثي اللغة اليابانية الباكرين كانوا أعاجم لا يقدرون على نطق الكلمات الآلطائية ذات المقطعين المغلقين المتتاليين. بالنسبة لهم المقطع الأول يجب أن ينتهي بصوت أنفي حتى يكون قابلا للنطق. ما هي اللغات التي تشترط أن يكون المقطع الأول منتهيا بصوت أنفي؟ الجواب هو لغات حملة العلامة Haplogroup O. أنا ذكرت في الأعلى أن الكلمات في هذه اللغات تأخذ الشكل C₁V₁N–C₂V₂(C₃) (حيث المقطع C₁V₁N– هو سابقة prefix أو “مقطع أصغر” minor syllable). المقاطع الصغرى التي من الشكل CVN– هي شائعة خصوصا في اللغات الأَوسترۆ-آسيوية. حسب Baxter & Sagart (2014) فإن المقاطع الصغرى في اللغة الصينية القديمة Old Chinese كانت دائما من الشكل C(ə)–، أي أنها لم تكن تنتهي بصوت أنفي.
عناقيد أصوات الصحة
ذكرت سابقا أن المقاطع الآلطائية تأخذ الشكل التالي:
C₁V(C₂)
أصوات الصحة المتجاورة أو “عناقيد أصوات الصحة” consonant clusters هي ممنوعة في المقاطع الآلطائية. على سبيل المثال، المقاطع من الشكل C₁C₂V– هي ممنوعة في اللغات التركية. الأتراك المعاصرون يغيرون بنية مثل هذه المقاطع بإضافة صوت علة دخيل epenthetic vowel (كلمة ἐπένθεσις epénthesis تعني “إدخال” insertion). مثلا الكلمة الفرنسية station أصبحت في التركية الأناضولية المعاصرة هكذا istasyon (أضيف صوت علة دخيل قبل العنقود الذي في بدايتها). المقاطع من الشكل (C₁)VC₂C₃ هي أيضا ممنوعة، والتعامل معها يتم بإضافة صوت علة دخيل في وسط العنقود (هذا الأسلوب يسمى “الفَرْد” anaptyxis). مثلا كلمة “اسم” العربية هي في التركية الأناضولية المعاصرة بهذه الصورة isim (عنقود السين والميم فُرد بإضافة صوت علة دخيل في وسطه). كلمة “عقل” هي بهذه الصورة aḳïl، وكلمة “وقت” هي بهذه الصورة vakit. عند إضافة لاحقة تبدأ بصوت علة إلى مثل هذه الكلمات فإن صوت العلة الفارد anaptyxic vowel يختفي؛ مثلا ismi و aḳlï و vakti. المقاطع من الشكل (C₁)VC₂C₂ يتم التعامل معها بحذف صوت الصحة المكرر (هذا يسمى “التسهيل” simplification أو “إزالة التوأمة” degemination). مثلا كلمة “حد” هي بهذه الصورة had، وكلمة “حق” هي بهذه الصورة haḳ، وكلمة “خط” هي بهذه الصورة hat. عند إضافة لاحقة تبدأ بصوت علة إلى مثل هذه الكلمات فإن صوت الصحة المحذوف يظهر مجددا؛ مثلا haḳḳï و haddi و hattï.
المقاطع من الشكل (C₁)VC₂C₃ هي مقبولة في اللغات التركية إن كان الصوت C₂ صوتا سائلا liquid (اللام والراء) أو أنفيا nasal (الميم والنون) أو هسيسيا sibilant (السين والشين). ما يلي أمثلة من اللغة الأناضولية المعاصرة مع معانيها:
| first أول | ilk |
| Turk تركي | Türk |
| adhesive لاصق | zamk |
| young شاب | gänᵗš |
| top قمة | üst |
| love عشق | ašk |
András Róna-Tas يرى أن مثل هذه الاستثناءات لم تكن موجودة أصلا في اللغات التركية ولكنها نشأت بسبب تطورات ثانوية. مثلا كلمة and التي تعني “عهد” oath (في الأناضولية المعاصرة ant) كانت ربما في الأصل هكذا *anda، بدليل أن اللغة المنغولية تحوي كلمة anda بمعنى “أخ محلّف” sworn brother.
الجزء التالي
مصادر
- Walter de Gruyter (1986), Language Universals, Markedness Theory, and Natural Phonetic Processes, p.78 ⏫
- The Cambridge History of Ancient China (1999), p.49 ⏫
- The Turkic Languages (1998), edited by Lars Johanson, Éva Csató
- The Mongolic languages (2003), edited by Juha Janhunen
- Marcel Erdal (2004), A Grammar of Old Turkic
- S. A. Starostin, A. V. Dybo, O. A. Mudrak (2003), An Etymological Dictionary of Altaic Languages
- Nicholas Poppe (1965), Introduction to Altaic Linguistics
- Peter B. Golden (1992), An Introduction to the History of the Turkic Peoples
- The Cambridge history of early Inner Asia (1990)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
النسخة الأولى التي نشرتها من هذا المقال سقط منها سهوا مقدمة المقال التي تحمل عنوان “بنية الكلمات”. لقد أضفت هذه المقدمة الآن.